Human-AI Copilot Optimization (HACO)
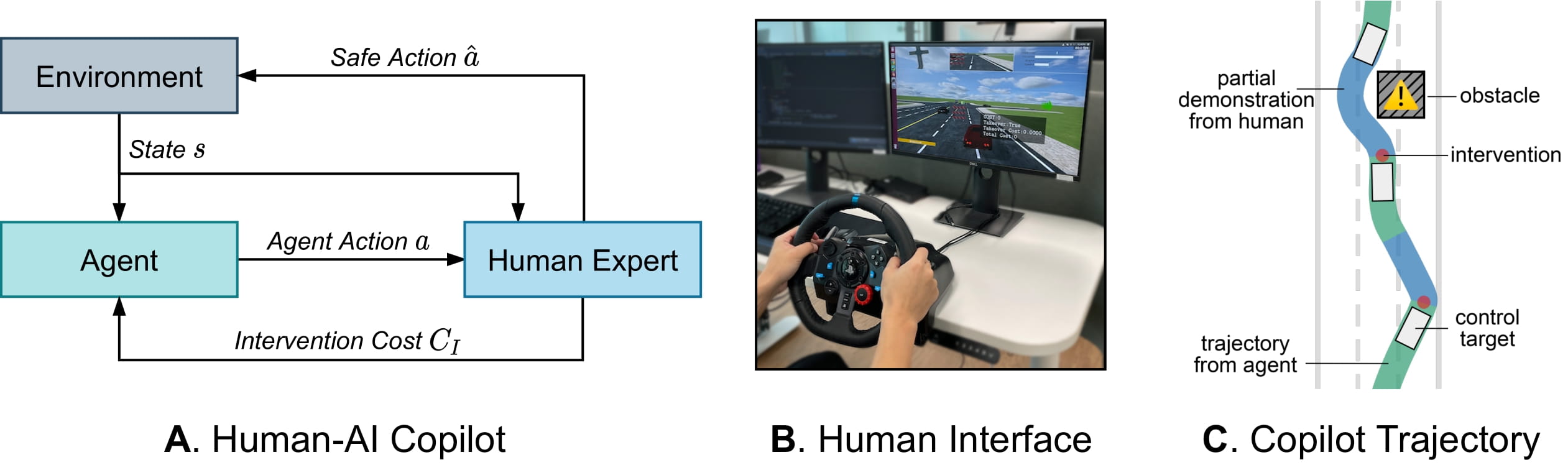
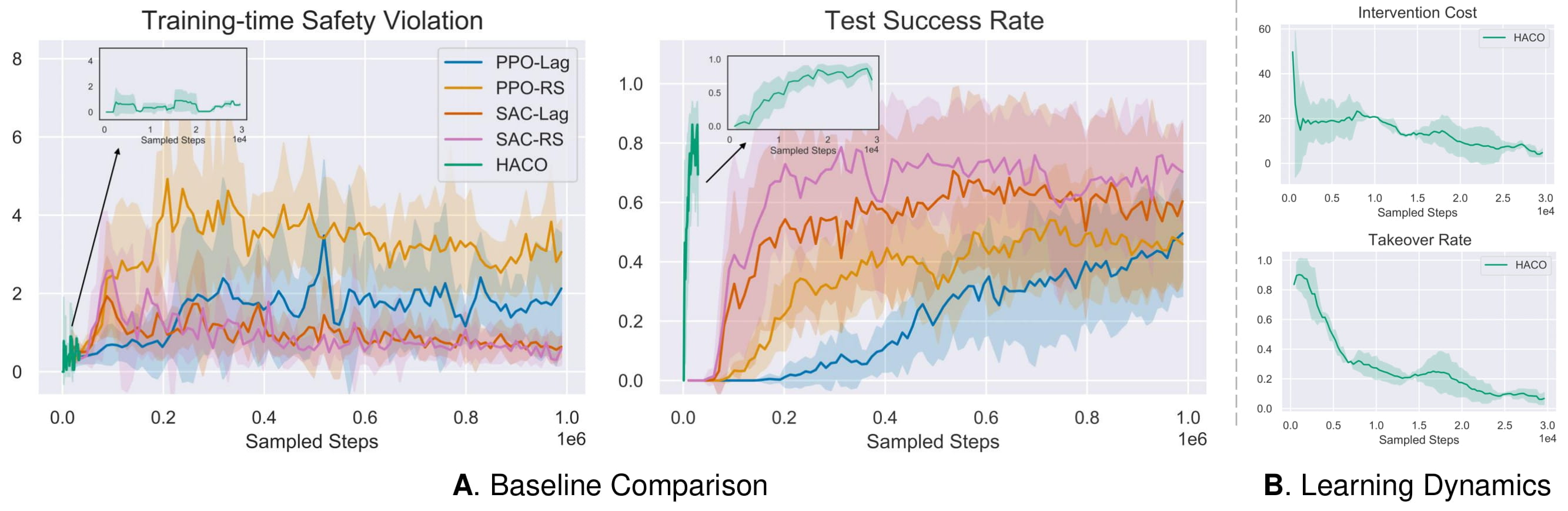
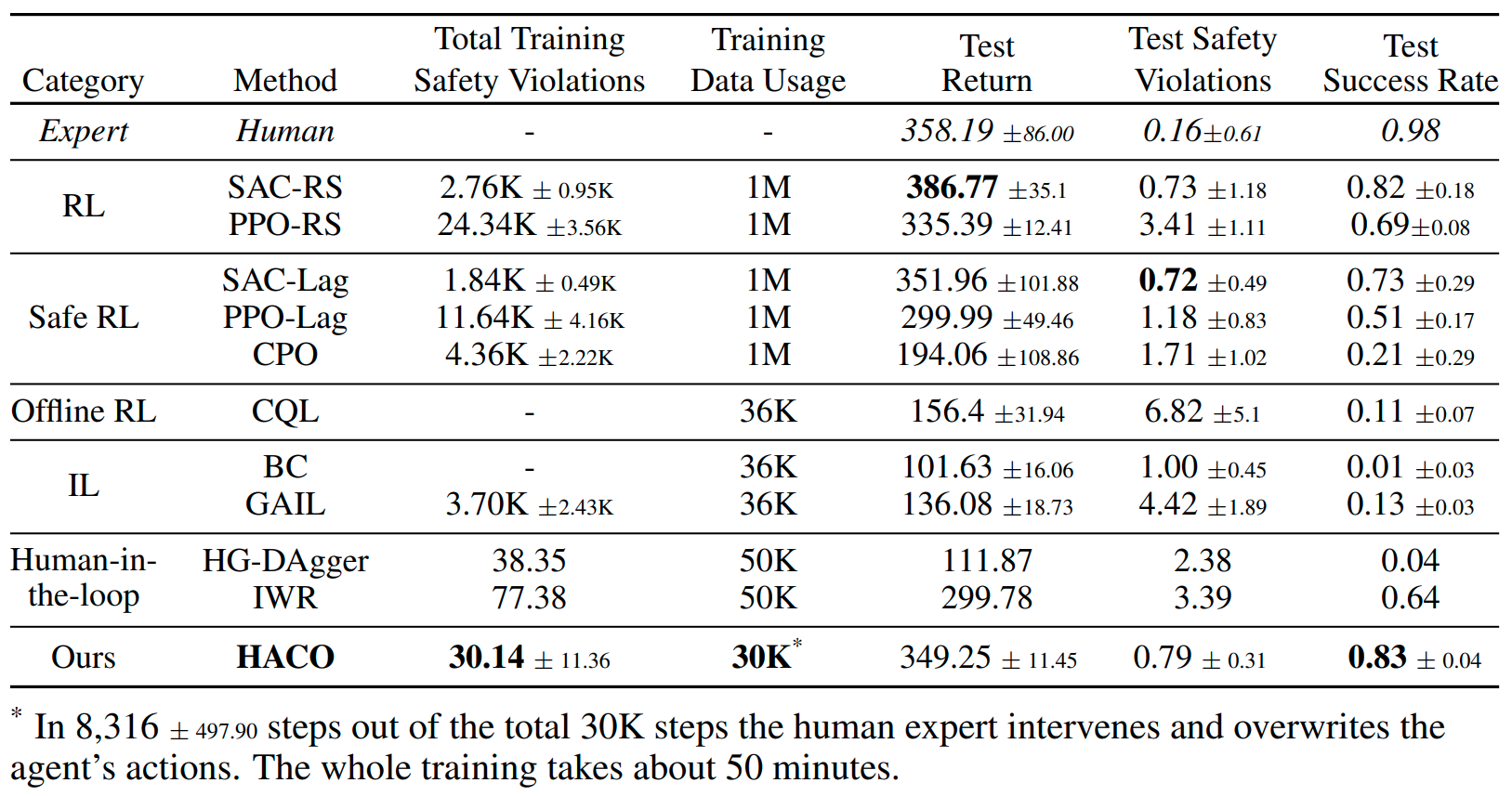
We develop an efficient Human-AI Copilot Optimization method (HACO), which incorporate human into the Reinforcement Learning (RL) training loop to boost the learning efficiency and ensure the safety. Sidestepping the requirement of complex reward engineering, HACO injects the human knowledge extracted from partial demonstration into the proxy value function by Offline RL technique. On the other hand, entropy regularization and intervention minimization are used for encouraging exploration and saving human budget respectively. The comprehensive experiments show the superior sample efficiency and safety guarantee of the proposed method.