

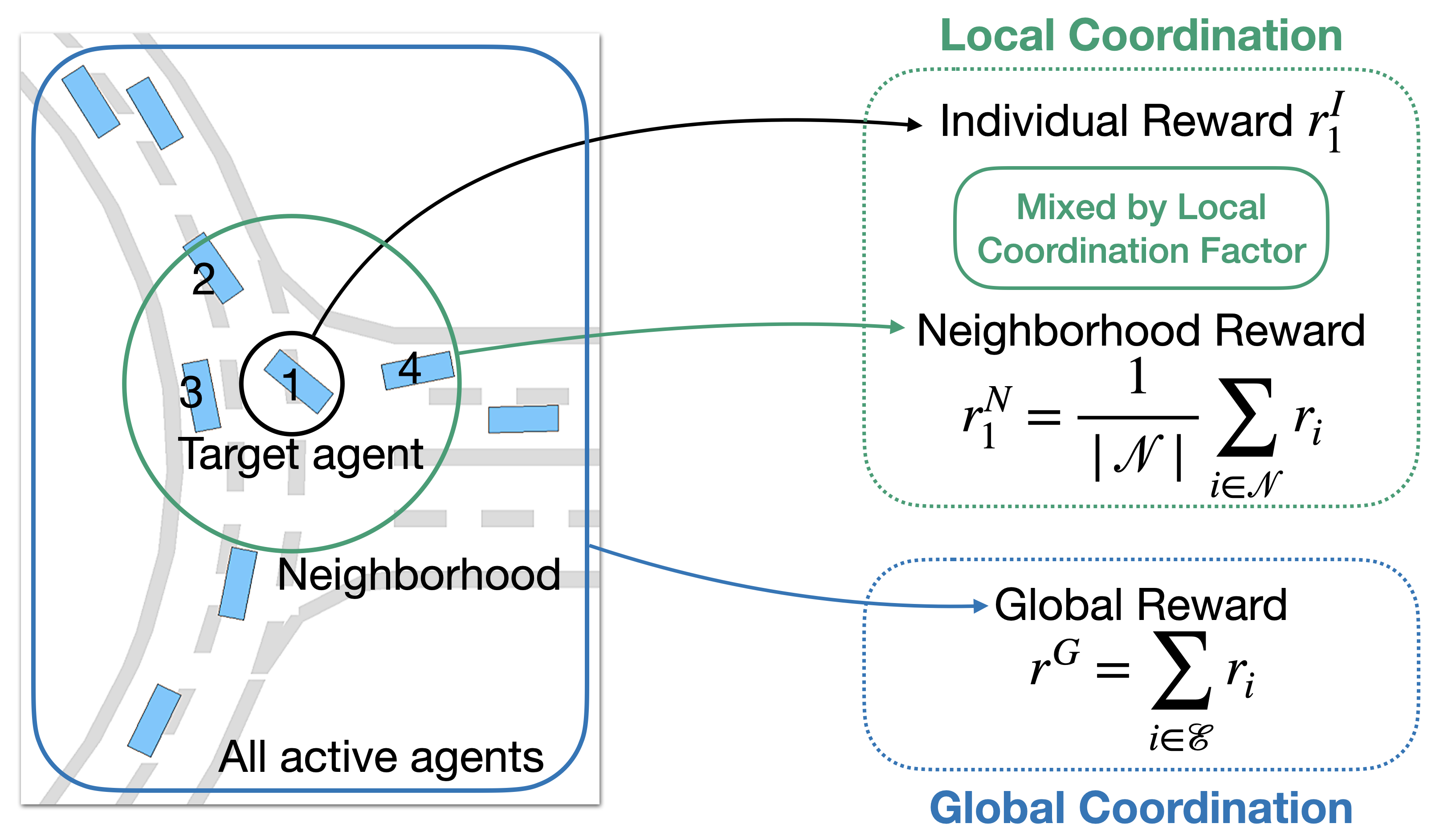
We develop a novel MARL method Coordinated Policy Optimization (CoPO) to facilitate the bi-level coordination of agents to learn the controllers of the Self-driven Particles systems, especially traffic flows.
CoPO consists of the Local Coordination, a mechanism to coordinate agents' objectives in neighborhood by use local coordination factor (LCF) to weight the individual reward and the neighborhood reward, and the Global Coordination, which uses meta-gradient to update LCF.
CoPO can learn realistic crowd actions as well as safe and socially compliant driving skills.
